

ゼロから学ぶ「フォントのしくみ」③:Std、Pro、Pr5、Pr6……フォントの文字セットとは?

フォント開発のエキスパート“ぬし"と、新入社員のケンによるフォント講座「ゼロから学ぶ『フォントのしくみ』」。第3回は、ぬし曰く、フォントメーカーにとっての最重要キーワード「文字セット」について解説します。

この記事ではフォントワークスの見解に基づくフォント知識を紹介しています。メーカー等によって見解が異なる場合がありますのでご了承ください。
“定義”された文字の集合「文字セット」
ケン 前回「文字セット」という言葉が出てきました。
ぬし 文字セットは、定義された文字の集合のことです。キャラクターセット、文字集合と呼ばれることもありますね。
日本語漢字を例に挙げるとJIS規格の文字セットでは、特に使用頻度の高い文字が含まれる第1水準漢字には2,965字、第2水準漢字には3,390字が定められています(現在では第3・第4水準まで拡張)。
ケン 同じ文字セットに対応したフォント同士なら、「こちらのフォントに入っている文字が、もう一方のフォントでは表示されない」ということを避けられますね。
ぬし その通りです。では、第3水準漢字が必要なときに、第2水準漢字までしか対応していないフォントで表示してしまうと、どうなるでしょうか?
ケン それは当然、第3水準の漢字が表示されない……のではないですか?
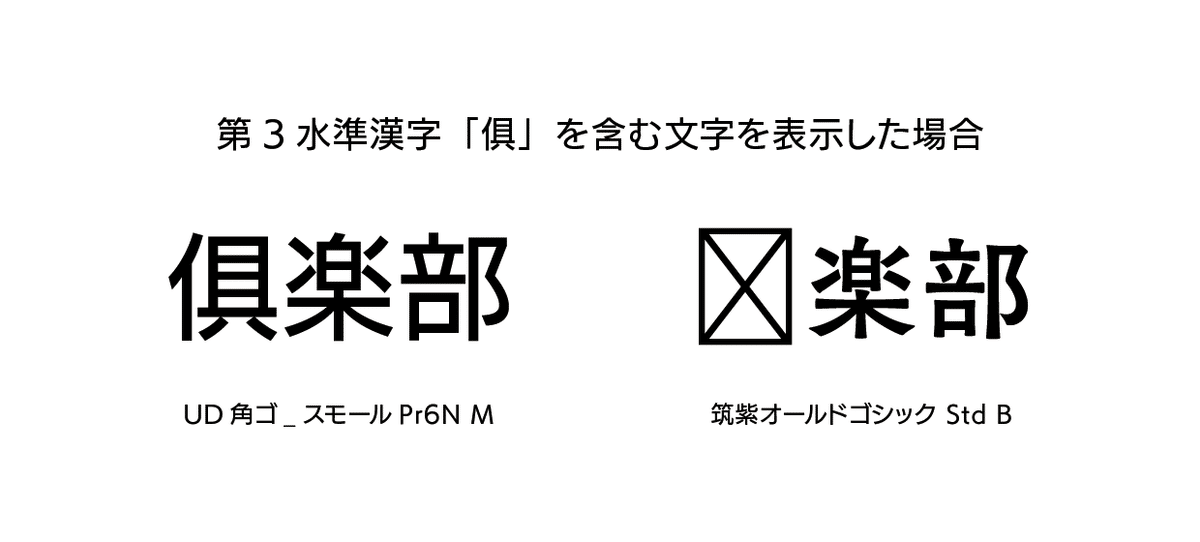
ぬし ええ、そうなります。「足りない文字は自作してでもこのフォントを使いたい」ということもあるかもしれませんが、基本的にフォントを選ぶ際、最も大事なのは「表示したい文字が全て表示されること」です。
私たちメーカーにとっても、フォントを選ぶデザイナーの皆さんにとっても、文字セットはとても重要な特徴なのです。
コンピュータで文字を扱うための「文字コード」
ぬし コンピュータで使用される文字には、一つ一つに“符号”が割り振られています。この符号を「文字コード」と呼びます。
ケン あ!「U+3042」みたいなやつのことですか?
ぬし それはUnicode(*1)で「あ(U+3042)」を示しますね。「U+」はUnicodeであることを示す記号で、さらに符号は一つの数を表し、この例の場合には後ろの16進数「3042」となります。文字コードは符号そのもの(3042の部分)を指すときと、その符号をつける仕組みを指すことがあります。Unicodeも文字コードの一つです。
そしてUnicodeは「符号化文字集合」でもあります。
ケン ふ、ふごうかもじしゅうごう……。
ぬし ふふふ。そんなに難しいものではないですよ。符号化文字集合とは、符号が割り振られている文字セットのことです。Unicode以外にも、日本語だとJISが定義しているJIS X 0208といった符号化文字集合があります。

ケン JIS X 0208の符号は、Unicodeとは全く違いますね。
ぬし JIS X 0208では区と点の組み合わせで符号を表現します。コンピュータで扱う文字が増えたため、その後に登場したJIS X 0213では面・区・点の組が用いられるようになりました。
かつてのコンピュータでは、日本語を表現できる文字コードとしてJIS X 0208を変換することで得られるShift-JISが使用されていましたが、現在は多くのコンピュータでUnicodeが採用されています。
*1 Unicodeとは、文字コードの国際的な標準規格の一つ。非営利団体のユニコードコンソーシアムによって構築や普及が行われている。
日本語フォントを支える「Adobe-Japan1」
ぬし さて。フォントワークスを含め日本語フォントメーカーの多くは、フォントに含まれる文字の形を集めてリストした「Adobe-Japan1」を採用しています。
ケン どういうことですか?
ぬし 「文字セット」とは、ある基準で定義された“文字の集合”ですが、Adobe-Japan1は少し違うものです。たとえば、Adobe-Japan1にはこのような文字の形が含まれています。

これらは全て大文字の「A」という文字ですね。つまり、Adobe-Japan1は文字の集合だけを定義しているわけではないということになります。
ケン 文字を体系化していく文字セットとは、ちょっと考え方が違いそうです。それぞれの文字がもつことのできる具体的な形のバリエーションを集めたものなのですね。
ぬし そうですね。漢字の例をあげると、Adobe-Japan1には文字コードU+82A6が割り振られた文字の形として、次の二つの形が含まれています。

上の漢字は、同じ文字でも異なる「字体」が区別されて収録されている例です。この「字体」を含めた文字の形のバリエーションのことを専門用語では「グリフ」と呼んでいます。ですから、Adobe-Japan1は、正確には「文字セット」ではなく「グリフセット」と呼んだ方が正確ですね。
フォントを使う上でも、異なる字体を使い分けると便利な場合があるので、フォントワークスではAdobe-Japan1を基準にしてフォントに含まれる文字の形を表しています。
ちなみにAdobe-Japan1を採用しているフォントには、文字コードとは別にそれぞれのグリフにCID(Character Identifier)という番号が割り振られていて、すべてのグリフを区別して示すことができます。例えばCID8753は「縦組み用回転字形の“A”」のグリフを表します。
ケン Adobe-Japan1のCID番号ってかなり多くなりそうです。どれくらいの数があるんですか?
ぬし 最新のAdobe-Japan1-7では0〜23059まであります。Adobe-Japan1-0から始まって、これまで7回にわたって、新しいグリフとCID番号が追加されてきました。ですが、全てのフォントをAdobe-Japan1-7に対応させる、つまり23,060グリフも制作するのは……。
ケン うう、それは大変です。
ぬし 一般的な用途で、Adobe-Japan1-7でないと必要なグリフがカバーできないケースは多くありません。ですから、それよりも収録グリフ数が少ないAdobe-Japan1-3やAdobe-Japan1-5に準拠したフォントもリリースしています。次の項目では、その見分け方を解説していきましょう。
収録グリフ数や字形の違い
フォントのグリフセットを確認しよう!
ケン フォントのグリフセットにAdobe-Japan1を採用しているとのことですが、LETSのフォント一覧を見ると、文字セットの欄には「Std」とか「Pr6N」などと書かれています。これはどう関係しているんですか?
ぬし 下の一覧を見てもらうのが早いでしょう。フォントワークスでは、以下のようにグリフセットの名称とAdobe-Japan1の規格とを対応させています。

ケン Nの有無については連載の第2回で解説してもらいました。なので、同じ書体でもProとProNがある、というのは理解できます。
しかし、例えば弊社のフラッグシップ書体「筑紫明朝」にはPro・Pr5・Pr6(*2)のバージョンがありますよね。一番文字数が多いPr6だけあればいいのではないですか?
ぬし それについては、少し開発背景を説明しなければなりません。
筑紫明朝は2002年にProでリリースされました。同じ年にAdobe-Japan1-5が発表されたため、すぐにPr5を開発し、その最中にAdobe-Japan1-6が発表され……という流れでPro・Pr5・Pr6が存在しています。
ケン うーん、それは分かりますが、現時点ではやはりPr6だけあればいいのでは?
ぬし 残念ながらPro・Pr5・Pr6のフォントは、システムではそれぞれ別のフォントとして認識されます。「筑紫明朝 Pro」が使用されているドキュメントを「筑紫明朝 Pr6」がインストールされたシステムで開いても、ProからPr6へ自動的に置き換わったりはしません。つまり、一度リリースしたフォントは、リリースし続ける責任があるのです。
ケン そうなんですね。気をつけないと、同じフォントだと思っていても、うっかりバージョンが違うものを選んでしまったりしそうです。目的に合ったフォントを選ぶためにも、文字セットやグリフセットについて理解しておくのは大事なことなのですね。
ぬし 文字セットや文字コードの世界はとても奥が深いので、本当は何日もかけて詳しく解説したいのですが……。
ケン そ、それはまたの機会にお願いします!
*2 筑紫明朝にはPro・Pr5・Pr6の他に、JIS X 0213:2004字形を初期設定の基本字形としたPr5N・Pr6Nがあり、OpenTypeフォントで5つのバリエーションがリリースされています。